강화학습의 혈관 속 탐험 시리즈
강화학습의 혈관 속 탐험 (1) - 로봇과 심혈관 중재 시술
강화학습의 혈관 속 탐험 (2) - 강화학습과 제어 이론의 비교
강화학습의 혈관 속 탐험 (3) - 실험환경 구성과 강화학습 알고리즘 소개
Intro
강화학습으로 특정 task를 학습하기 위해서는 에이전트가 될 강화학습 알고리즘을 선정하고 에이전트가 상호작용할 환경을 구성해야합니다. 이번 포스트에서는 저희가 강화학습으로 PCI 로봇을 제어하기 위해 사용한 알고리즘과 환경에 대해 소개하겠습니다.
실험 환경 구성
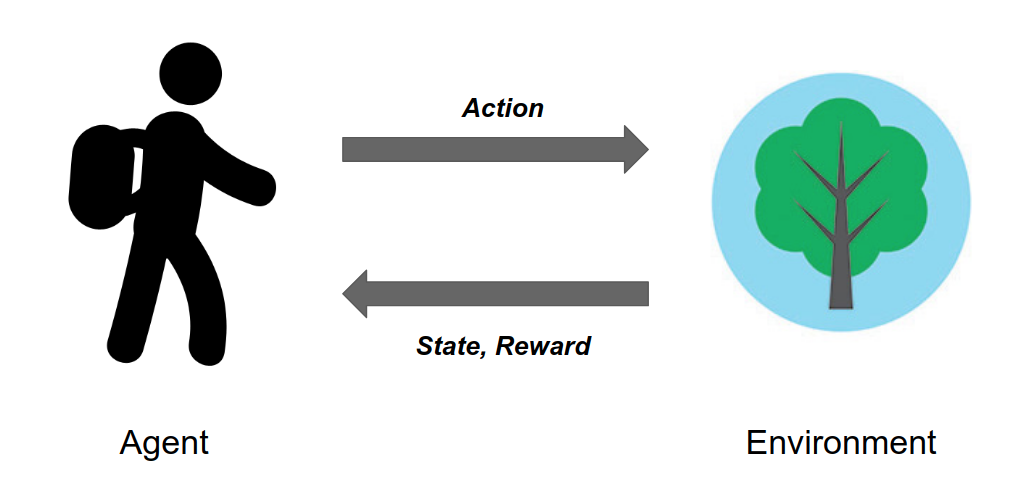
강화학습 에이전트(Agent)는 아래 그림과 같이 상태(state)에서의 행동(action)을 선택하고 얻는 보상(reward)을 통해 학습합니다. 이때 상태와 보상 등의 정보들을 환경과의 상호작용을 통해 얻습니다. 이러한 학습 프로세스를 그림으로 표현하면 아래 그림과 같습니다. 환경이 제대로 구성되지 않으면 어떤 강화학습 알고리즘을 쓰더라도 제대로 학습할 수 없습니다. 그렇기 때문에 강화학습에서 환경은 아주 중요한 개념입니다. 강화학습의 환경은 주로 우리가 풀고 싶은 문제를 시뮬레이터로 제작하여 가상 환경으로 구성하는 방법과 해당 문제를 실제 real world에서 반복 가능한 형태로 실험 환경을 구성하는 방법이 있습니다. 저희는 PCI에서의 가이드와이어 제어 문제를 풀고자 하기 때문에 시술 과정을 강화학습 에이전트가 상호작용 가능한 환경의 형태로 만들 필요가 있습니다. 이를 위해 PCI의 과정을 알아봅시다.
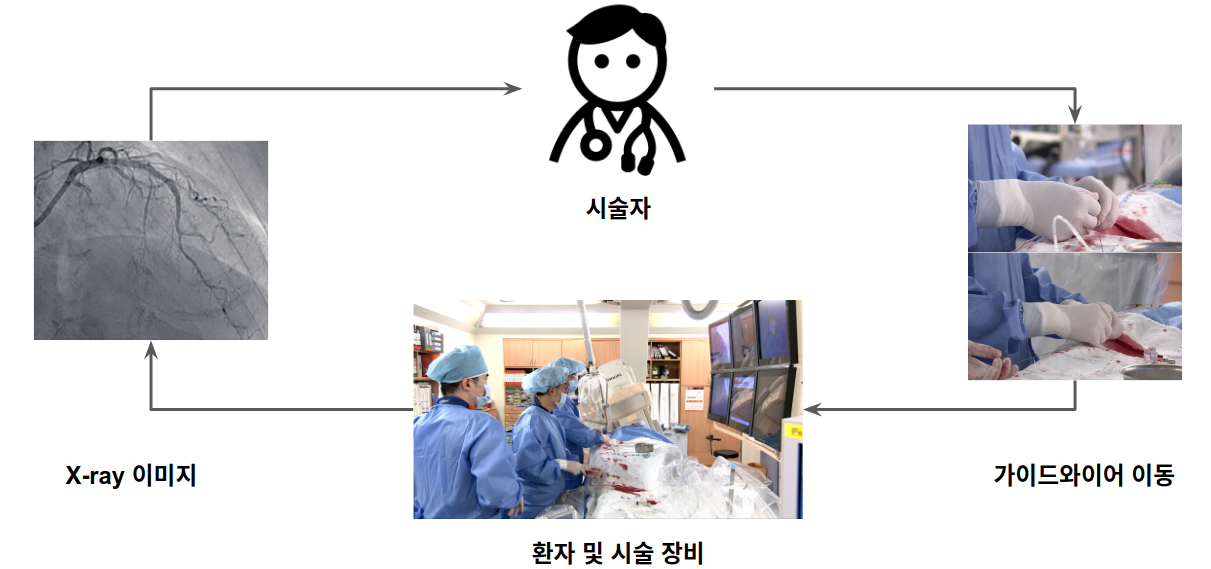
PCI 시술 환경
PCI 시술에서 시술자가 환자의 혈관 모양과 현재 가이드와이어의 위치를 X-ray 조영 영상을 통해 봅니다. 현재 병변 위치가 어디인지, 제어하고 있는 가이드와이어의 모양과 위치가 어디인지 등의 정보를 모두 2D 이미지를 통해 확인합니다. 시술자는 이미지 정보를 바탕으로 가이드와이어를 어떻게 움직여야 할지 판단합니다. 가이드와이어를 움직이면 다시 조영 영상이 바뀌게 되고 시술자는 영상을 보고 다시 와이어를 움직입니다. 숙련된 시술자는 이러한 과정을 굉장히 빠르게 수행하여 환자의 병변 부위를 치료합니다. 이런 프로세스를 위의 강화학습 프로세스에 맞게 표현하면 다음 그림과 같습니다 [1]. 시술자는 에이전트, 환자의 혈관과 X-ray 시술 장비가 환경, X-ray 조영 영상이 상태, 가이드와이어를 움직이는 것이 행동이 됩니다.
PCI 시술에 대한 자세한 내용은 이전 포스트인 강화학습의 혈관 속 탐험 (1) - 로봇과 심혈관 중재 시술을 참고하시기 바랍니다.
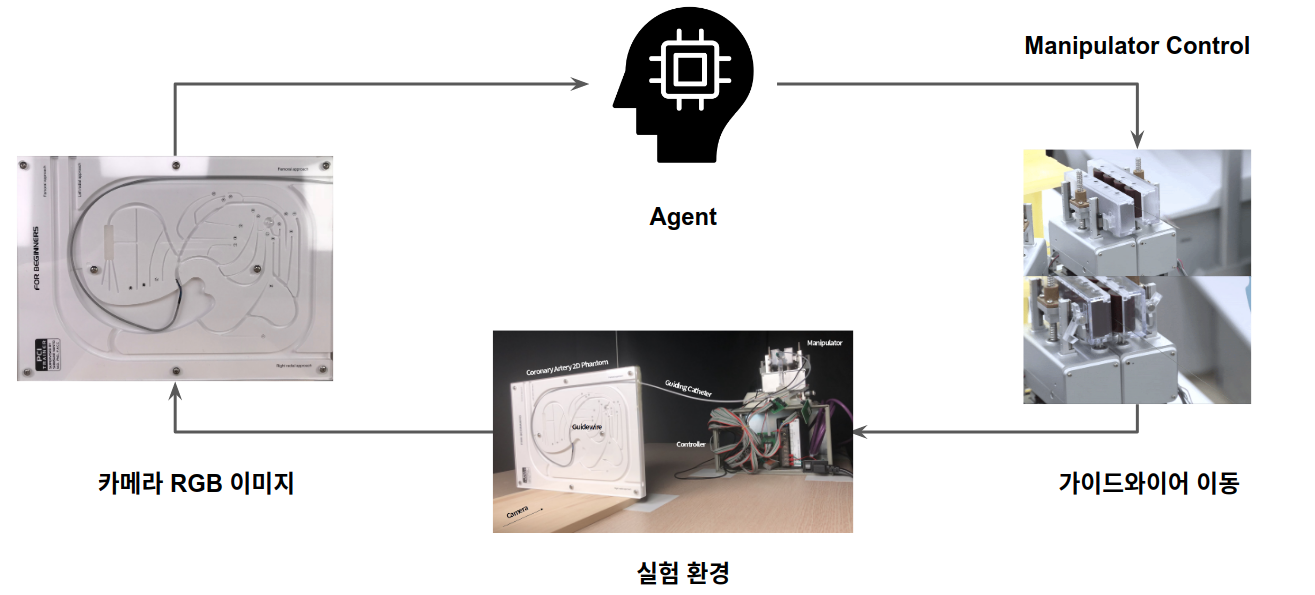
혈관 모형을 이용한 실험 환경 구성
이전 포스트에서 언급한 것처럼 PCI 시술은 가이드와이어의 마찰, 사람의 호흡, 심장의 박동 등의 이유로 모델링이 굉장히 어렵습니다. 모델링이 어렵다는 것은 다시 말해 시뮬레이터와 같은 가상 환경으로 제작하기 어렵다는 뜻입니다. 따라서 저희는 시뮬레이터보다는 혈관 모형을 이용한 real world 실험 환경을 구성하였습니다. 실제 시술에서 의사가 X-ray 이미지를 보고 가이드와이어를 어떻게 제어할 지 판단하듯이 강화학습 에이전트는 2D 혈관 모형의 이미지를 보고 결정합니다. 결정한 제어 신호를 PCI 로봇으로 전달하여 실제 가이드와이어를 제어하게 됩니다. 이를 위의 시술 과정 프로세스와 같이 표현하면 아래 그림과 같습니다. 강화학습 알고리즘이 에이전트, 로봇과 2D 혈관 모형이 환경, 2D 혈관 모형 이미지가 상태, 가이드와이어 제어 로봇을 움직이는 것이 행동이 됩니다.
알고리즘 선정
이렇게 강화학습 에이전트를 학습시키기 위한 환경이 준비가 되었습니다. 이제 에이전트가 상호작용할 환경이 준비가 되었으니 이제 어떤 에이전트를 학습시킬 것인가를 결정해야합니다. 즉, 어떤 강화학습 알고리즘을 쓸 지 결정해야합니다. 현재까지도 굉장히 많은 강화학습 알고리즘들이 연구되고 있고 각 알고리즘들마다 특성이 다르고 장단점이 있기 때문에 저희 환경에 적합하고 저희가 실험하고자 하는 방향과 맞는 알고리즘을 선택할 필요가 있었습니다. 여러가지 고려사항 중 저희가 크게 고민했던 부분은 다음과 같습니다.
- On-policy vs Off-policy
- Human demo 활용 유 vs 무
- Discrete action vs Continuous action
On-policy vs Off-policy
On-policy와 Off-policy는 강화학습에서 많이 언급되는 내용 중 하나입니다. 이 두 가지 개념을 이해하려면 몇 가지 강화학습의 개념들을 알아야합니다.
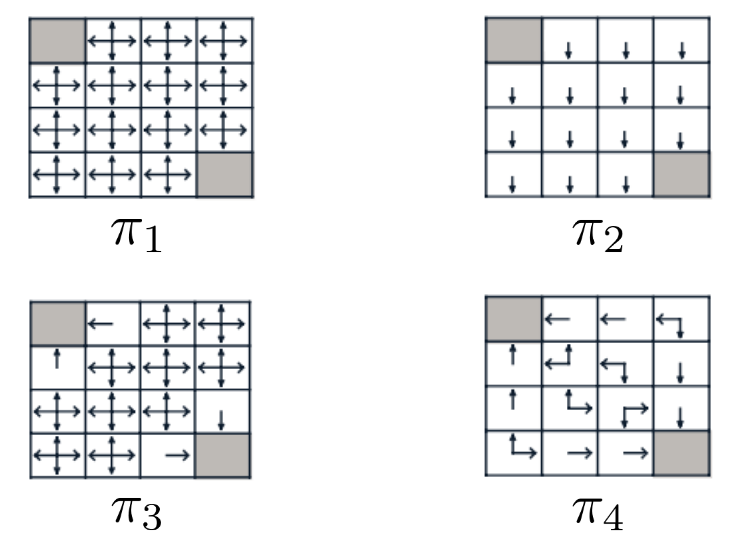
- 정책 (Policy): 강화학습에서 정책은 어떤 상태가 주어졌을때 행동에 대한 확률분포를 말합니다. 정책은 학습을 통해 우리가 원하는 더 좋은 정책으로 만들 수 있습니다. 만약 현재 정책이 최적의 정책이라면 이 정책으로 모든 상태에 대해서 행동을 했을 때 가장 높은 누적 보상을 받게 됩니다. 아래 이미지에서 정책의 예시를 표현하였습니다. 각 네모칸이 상태이고 회색 네모칸이 보상을 받는 상태라고 한다면 $\pi_4$가 최적의 정책이라 할 수 있습니다.
아래 이미지에서 정책의 다른 예시를 보여줍니다. 각 상황에서 캐릭터가 죽지 않으려면 점프하는 행동이 가장 확률이 높아야합니다.

이 아래부터는 정책이라는 단어보다 policy라는 단어를 사용하도록 하겠습니다.
- 경험 (Experience): 강화학습 알고리즘을 학습하기 위해서는 환경과 상호작용해서 얻은 상태와 행동, 보상 등의 경험(experience)을 얻어야 합니다. 이러한 경험들이 강화학습에서의 데이터라고 할 수 있습니다.
On-policy는 학습하는 policy와 행동하는 policy가 같은 알고리즘을 말합니다. 즉, On-policy는 현재 학습하는 policy를 통해서 얻은 경험만을 이용해 학습할 수 있습니다. 다른 policy가 얻은 경험 뿐만 아니라 과거의 policy로 얻은 경험 또한 사용할 수 없습니다. Off-policy는 이와 반대로 학습하는 policy와 행동하는 policy가 다른 알고리즘을 말합니다. 현재 학습하고 있는 에이전트가 과거에 모았던 경험 뿐만 아니라 지금 학습하고 있는 에이전트와 완전히 다른 에이전트가 만든 경험들까지도 학습에 사용할 수 있습니다.
딥 강화학습 알고리즘에서 on-policy와 off-policy는 experience replay의 사용 여부에서 차이가 납니다. Experience replay는 환경을 통해 얻은 경험들을 버퍼에 쌓고 batch 단위로 샘플링하여 학습하기 때문에 off-policy 방법이라고 할 수 있습니다. 딥 강화학습에서 on-policy는 대표적으로 TRPO [2], PPO [3]가 있으며 off-policy는 DQN [4], DDPG [5]가 있습니다. 아래 이미지는 experience replay를 사용하는 off-policy 알고리즘의 학습 사이클을 설명합니다.
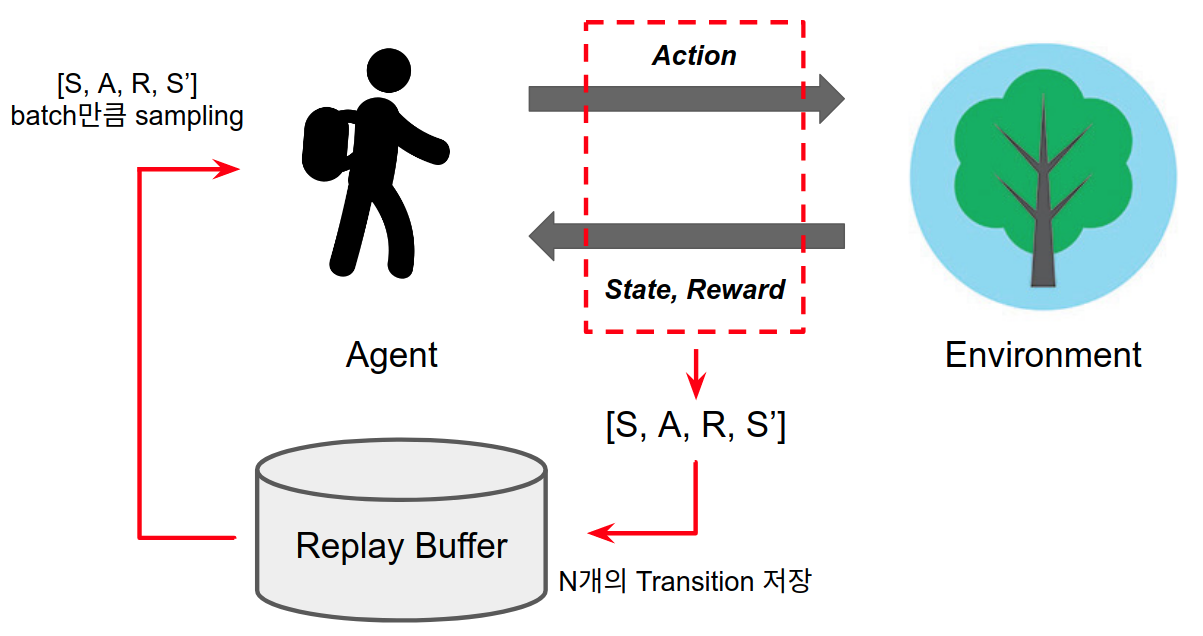
PPO와 같은 On-policy 알고리즘은 이전 경험을 사용할 수 없기 때문에 현재 데이터를 많이 모으기 위해서 주로 환경을 분산처리시키는 방법을 사용합니다. 그렇지 않으면 과거의 데이터를 사용할 수 없기 때문에 off-policy와 학습 속도에서 차이가 나게 됩니다. 하지만 저희가 구축한 환경은 가상 시뮬레이션 환경이 아닌 real world 환경이기 때문에 분산처리 환경을 구축하기가 어렵습니다. 4개의 환경을 분산처리 하려면 4개의 로봇과 혈관 모형, 카메라 세트가 필요하기 때문이죠. 이러한 이유로 저희는 real world 환경에서는 off-policy 알고리즘이 적합하다고 생각하였습니다.
Human demo 활용 유 vs 무
Off-policy 알고리즘은 현재 학습하고 있는 에이전트가 모은 경험 뿐만아니라 다른 경험 또한 학습 데이터로 사용할 수 있습니다. 이는 에이전트가 아닌 사람이 만든 경험도 마찬가지입니다. 강화학습 에이전트는 학습 초기에는 환경을 탐험해도 무작위 행동과 같은 수준의 경험만을 모을 수 있습니다. 이러한 경험들도 물론 학습에 유용한 경험들이지만 무작위 행동만으로 해당 환경의 목표(goal)에 도달하는 경험을 많이 얻는 데에는 오랜 시간이 필요합니다. 그런데 만약 이미 숙련된 사람이 만든 경험을 학습에 사용할 수 있다면 어떨까요? 특정 환경에 숙련된 사람이 만든 경험은 에이전트 입장에서는 완벽히 이상적인 경험이 아닐 수도 있지만 적어도 학습 초기의 에이전트보다는 훨씬 좋은 경험일 것입니다. 또한 환경의 목표(goal)에 도달하는 경험이기 때문에 무작위로 탐험한 경험만을 이용해 학습하는 것보다 훨씬 빠르게 에이전트를 학습시킬 수 있습니다. 이런 사람이 만든 경험을 human demonstration 이라고 합니다.
강화학습에 human demo를 사용해서 학습 성능을 높히려는 연구가 많이 되고 있습니다 [6, 7, 8]. 특히 저희의 환경은 real world 환경이기 때문에 가상 환경에 비해 환경의 안정성을 보장하기 어렵습니다. 예를 들어 장시간 학습을 돌리다 보면 로봇에 이상이 생기거나 가이드와이어, 카테터와 같은 의료 도구들이 파손되어 같은 행동을 해도 기존과는 다른 동작이 되는 경우가 생깁니다. 이를 방지하기 위해서는 최대한 학습 속도를 빠르게 하는 것이 중요합니다. 빠른 학습이 환경의 안정성을 높히는 길인 것이죠. 따라서 저희는 human demo를 활용한 알고리즘을 사용하기로 하였습니다.
Discrete action vs Continuous action
강화학습에서의 행동은 Discrete action과 Continuous action으로 나눌 수 있습니다. 알고리즘에 따라 특정 action space는 학습이 아예 불가능한 경우도 있기 때문에 강화학습 알고리즘을 선정할 때 중요한 요인 중 하나입니다.
Discrete action
- Discrete 하게 결정되는 행동을 말합니다. 즉, 중간 값이 없고 0 또는 1의 값을 갖습니다.
- 예를 들어, [전진, 후진, 회전] 이라는 행동이 있을 때 전진 행동은 [1, 0, 0]과 같이 선택합니다.
- 중간 값은 없으며 Discrete action으로 다양한 행동을 표현하려면 행동의 개수를 늘려야합니다.
- 예시: [전진 1cm, 전진 2cm, 후진 1cm, 후진 2cm, 회전]
- 주로 Q learning과 같은 value-based 알고리즘으로 학습합니다.
Continuous action
- Continuous action은 실수 값을 가지며 값의 크기를 표현할 수 있습니다.
- 예를 들어, [전/후진, 회전] 이라는 행동이 있을 때 [0.3, 0.4]과 같이 전/후진, 회전 값을 실수 값으로 지정할 수 있습니다.
- 행동 값의 범위가 무한하기 때문에 action space의 크기가 큽니다.
- 주로 Policy gradient와 같은 policy-based 알고리즘으로 학습합니다.

저희가 구성한 혈관 모형 환경에서 action space를 결정하기 위해 저희가 고려한 사항은 다음과 같습니다.
- PCI 로봇의 동작: 기계 구조상 전진과 회전 동작을 동시에 조작할 경우 가이드와이어가 이탈하거나 꼬일 위험이 있음.
- human demo 제작의 용이성: 키보드 입력으로 손쉽게 human demo의 생성이 가능해야함.
- 중간 값의 필요성: 혈관 모형 환경에서는 전진과 회전 값의 scale을 고정하는 것이 더 유리하다고 판단함.
이외에도 여러 상황을 고려했을 때 혈관 모형 학습 환경은 discrete action으로 구성하여도 충분하다고 판단하였습니다.
따라서 off-policy + discrete action인 DQN을 학습 알고리즘으로 선정하였습니다. DQN은 많은 연구를 통해 기존 DQN의 여러 단점을 보완한 다양한 변형 DQN들이 나왔는데 그 중 state-of-the-art로 알려진 Rainbow를 사용하기로 하였습니다. 추가로 human demo를 이용해 학습하는 아이디어인 from demonstration(fD) 알고리즘을 결합하여 RainbowfD로 최종 결정하였습니다 [9].
학습 결과
저희가 혈관 모형 환경을 구성한 환경과 에이전트의 최종 목표는 로봇으로 가이드와이어를 제어하여 원하는 위치까지 이동시키는 것이었습니다. 이를 학습시키기 위해 상태 이미지를 다양한 컴퓨터 비전 기술을 이용해 전처리하였습니다. 그리고 목표(goal)를 상태 이미지에 표시해주어 에이전트가 목표를 명확하게 알 수 있도록 해주었습니다.

이렇게 구성한 환경에서 선정한 RainbowfD 알고리즘을 통해 학습시킨 결과 가이드와이어를 원하는 위치까지 성공적으로 제어하였습니다! 학습 결과는 아래 영상을 통해 확인할 수 있습니다.
아래 영상은 TCT 2019 학회의 포스터 세션에서 발표한 영상입니다 [10].
마치며
이번 포스트에서는 강화학습으로 PCI에서의 가이드와이어 제어를 학습하기 위한 방법을 구체적으로 소개하였습니다. 강화학습으로 특정 문제를 풀기 위해서는 환경을 구축해야하고, 환경과 문제에 맞는 강화학습 알고리즘을 선택해야합니다. 이러한 환경 구축과 알고리즘 선정 과정에서 저희가 했던 방식을 설명하였습니다. 강화학습은 보통 게임이나 가상환경에서 학습한 예제는 많지만 실제 환경에 적용한 사례는 드뭅니다. 다른 환경에 강화학습을 시도하고자 하는 분들에게 저희가 시도하고 고민했던 방식이 한 가지 예시로써 많은 도움이 되기를 바랍니다. 이번 포스트를 끝으로 강화학습의 혈관 속 탐험 시리즈는 마무리됩니다. 차후 다른 내용으로 포스트 올리도록 하겠습니다.
이 포스트는 2019년에 RL Korea와 모두콘에서 발표한 “Rainbow의 혈관 속 탐험” 발표를 기반으로 작성하였습니다.
Reference
[1] CAG 이미지 출처: https://www.researchgate.net/figure/CAG-images-of-the-first-PCI-a-Coronary-stenosis-in-the-proximal-mid-portion-of-LAD_fig1_316498381
[2] TRPO: Schulman, John et al., “Trust region policy optimization.” In International Conference on Machine Learning (ICML), 2015a.
[3] PPO: J. Schulman et al., “Proximal Policy Optimization Algorithms.” arXiv preprint arXiv:1707.06347, 2017.
[4] DQN: V. Mnih et al., “Human-level control through deep reinforcement learning.” Nature, 518(7540):529–533, 2015.
[5] DDPG: T. P. Lillicrap et al., “Continuous control with deep reinforcement learning.” arXiv preprint arXiv:1509.02971, 2015.
[6] DQfD: T. Hester et al., “Deep Q-learning from Demonstrations.” arXiv preprint arXiv:1704.03732, 2017.
[7] DDPGfD: Mel Vecerik et al., “Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards.” CoRR, 2017.
[8] Behavior Cloning: A. Nair et al., “Overcoming Exploration in Reinforcement Learning with Demonstrations.” arXiv preprint arXiv:1709.10089, 2017.
[9] Rainbow: M. Hessel et al., “Rainbow: Combining Improvements in Deep Reinforcement Learning.” arXiv preprint arXiv:1710.02298, 2017.
[10] TCT 2019 Reinforcement learning for guidewire navigation in coronary phantom 포스터 자료: https://www.tctmd.com/slide/reinforcement-learning-guidewire-navigation-coronary-phantom