이번 posting에서는 competition에 적용하였던 reward shaping 방법론과 imitation learning 방법론을 기본으로 reward, penalty를 바꿔가며 했던 여러 가지 실험 결과에 관해 이야기해보겠습니다.
Reward shaping
Google deep mind에서 2015년 발표한 Human-level control through deep reinforcement를 보면 다양한 atari game environment에서 DQN의 성능을 볼 수 있습니다. montezuma’s revenge 같은 경우 거의 바닥에 수렴(randome play와 같은 수준)하는 결과치를 볼 수 있는데요. 이 게임은 stage를 클리어하기 위해 주인공 캐릭터가 거쳐야 하는 단계가 너무 복잡하고 많습니다. 이것을 강화학습 관점에서 이야기하면 reward가 너무 sparse 하여 강화학습 agent가 어떻게 상황을 헤쳐나갈 지에 대해 갈피를 잡지 못한다고 할 수 있습니다.
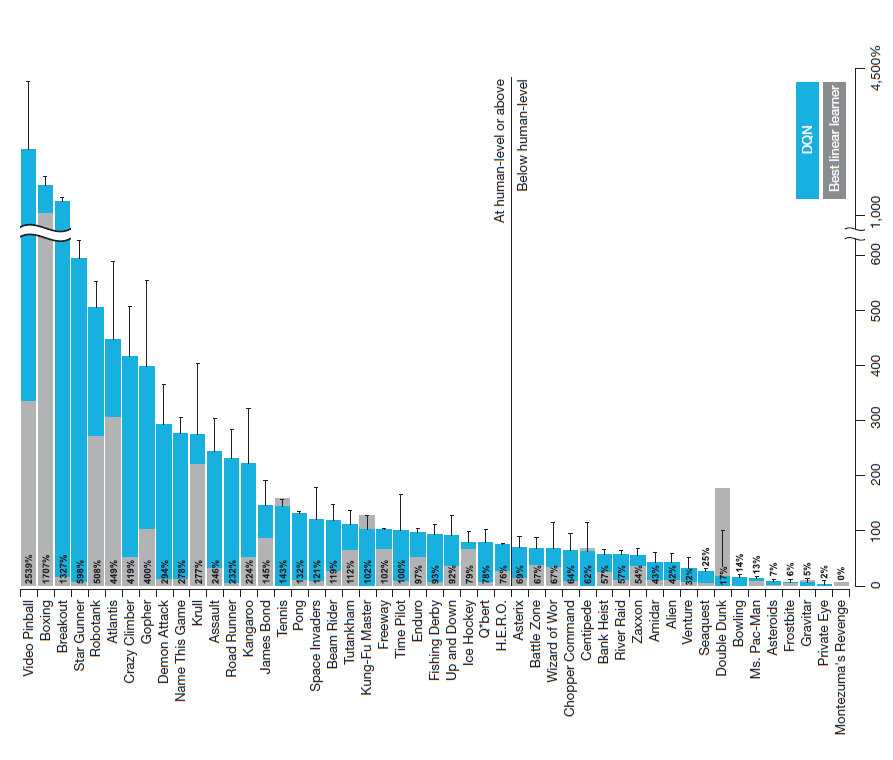
from Human-level control through deep reinforcement , V Mnih et al. 2015
그렇다면 어떻게 sparse 한 reward를 dense 하게 만들 수 있을까요? 크게 2가지 해결책이 있을 수 있습니다.
- manually design: 수작업으로 직접 reward function을 만듦
- learn from demonstration: 전문가의 demonstration trajectory를 모방하게 함
이번 competition에서도 위와 비슷한 문제가 있었습니다. 각 time step 별로 따라가야 할 속도는 나와 있었지만 나머지 정보는 전혀 없는 상태였죠. 특히 자세같은 경우는 상당히 중요한데, 현재의 자세가 다음 자세에 영향을 미치기 때문입니다. 이러한 연속적인 자세의 모음으로 원하는 속도가 제대로 나느냐 안 나느냐가 판가름 나기 때문에, 자세에 대한 상벌은 굉장히 중요한 요소였습니다. 우선 manually design 한 방식으로 접근하기 시작했습니다.
처음에는 아주 간단한 reward와 penalty부터 출발하였습니다. NIPS2017 competition solution에 공개된 후기들을 탐색한 결과 거의 모든 참가자가 적용하였던 부분이 있었습니다.
- 골반은 전방으로 기울어 져야 한다 -> pelvis의 각도
- 머리는 항상 골반보다 앞서 위치하여야 한다 -> head, pelvis의 위치
- 넘어지면 penalty
위 3가지를 넣고 수행하며 결과를 지켜봤는데, round 1 같은 경우 생각보다 괜찮은 결과물이 나왔습니다.
Imitation Learning
Learn from demonstration은 Imitation Learning이라고도 불립니다. manually design 전략에서 꽤 괜찮은 결과물을 내었지만, 더 정밀한 reward를 만들기 위해 얼마 안 가 Imitation Learning 관련 리써치를 시작하였습니다. 본격적으로 Imitation learning을 적용하기 시작했을 시기는 competition이 어느 정도 진행된 후였습니다. 앞선 Opensim posting에서 언급했던 것과 같이 여러 가지 시행착오를 겪으며 리써치를 수행한 후에야 어느정도 기본적인 Demonstration을 만들 수 있었기 때문이죠.
Demonstration으로 쓸 kinematics 데이터셋이 완성되었을 초기에는 이번 competition을 금방 끝낼 수 있을 것만 같은 착각에 빠져있었습니다. 아직 opensim에 대해 조사가 깊이 이루어지기 전이어서, opensim tool들을 사용해서 주어진 kinematics로부터 action을 만들어 낼 수 있다고 파악했기 때문이었죠. 다음 그림과 같이 말이죠.
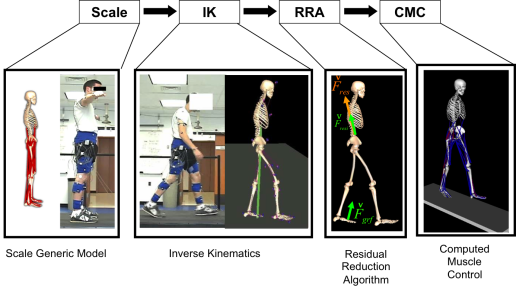
Behavioral Cloning
Brief description
우선 간단하게 Behavioral cloning(BC) 방법론에 대해 살펴봅시다. 기본 컨셉은 매우 간단합니다. 그 이름과 같이 agent를 사람과 같은 experts의 행동을 유사하게 따라 하게 만들겠다는 것입니다. End to End Learning for Self-Driving Cars를 보며 알아봅시다. 우선 training 과정부터 살펴보면 다음 그림과 같이 이루어지게 됩니다.
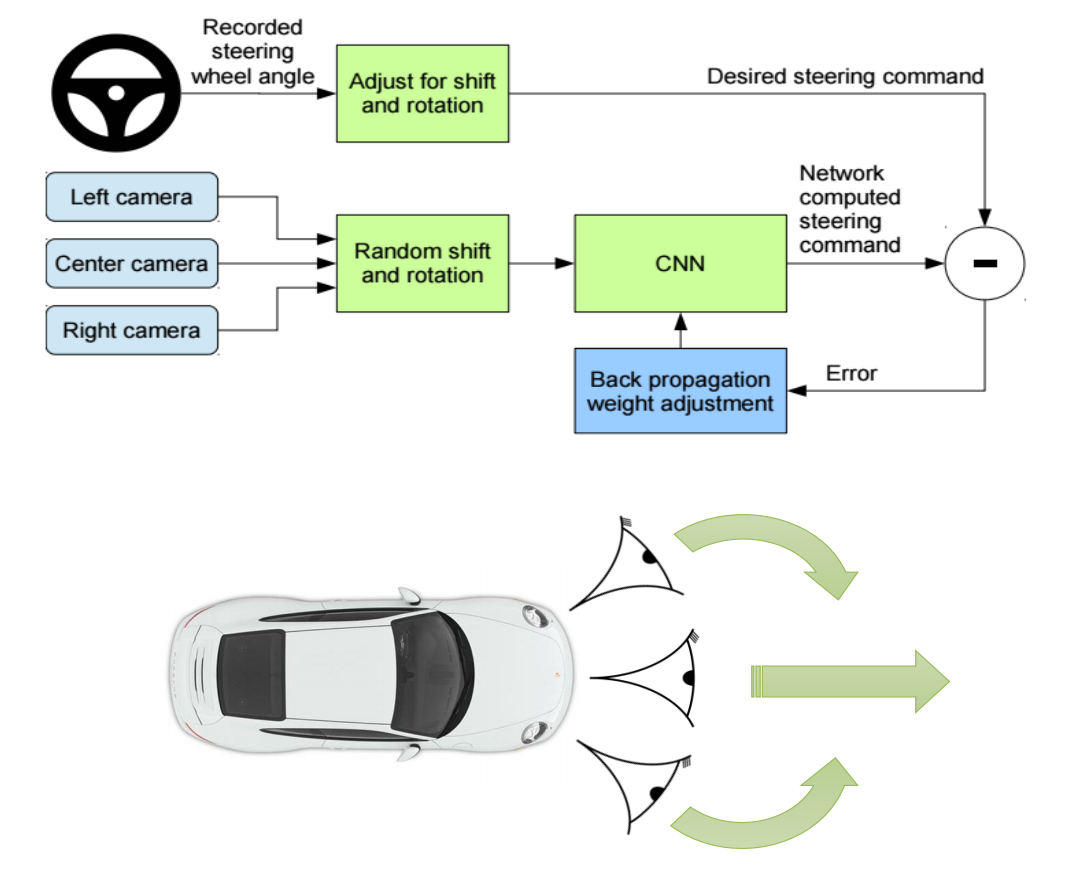
마치 Deep learning에서 CNN Classifier를 학습시키는 것과 유사한데요. Classifier 학습에 빗대자면 Input은 camera를 통해 들어오는 observation 데이터, Output은 steering command 라고 생각할 수 있습니다. 그리고 Label로 제시된 사람이 입력한 steering command와의 차이를 loss로 back propagation을 통해 학습됩니다. 정리하자면 다음과 같습니다.
- 사람의 운전 데이터 수집
- Left, Center, Right camera를 통해 observation 데이터를 수집
- steering wheel angle 녹화를 통해 action 데이터를 수집
- CNN 네트워크 학습
- Data augmentation:
- Left camera에서 수집된 데이터는 action에 우측으로 가는 bias를 더해줌(가운데로 가기 위해)
- Right camera에서 수집된 데이터는 action에 좌측으로 가는 bias를 더해줌(가운데로 가기 위해)
- 학습(supervised learning)
- Data augmentation:
학습된 agent를 이용한 test는 매우 단순합니다. 다만 이 방법론은 한계점은 train 데이터셋에서 볼 수 없었던 observation이 test 시에 입력되게 된다면, action에서 미정의 동작이 발생하게 됩니다. deep-learning과는 달리 시시각각 변하는 환경에서 데이터를 입력받기 때문에, 이런 확률은 상당히 높은 편에 속하죠. 정리해서 표현하자면 expert의 trajectory 데이터셋 $P_{\text{data}}(o_t)$ 와 agent가 현재 policy $\pi_{\theta}$를 통해 경험할 수 있는 trajectory 데이터셋 $P_{\pi_{\theta}}(o_t)$ 의 분포가 다르기 때문입니다. 식으로 표현하면 다음과 같습니다.
$$ P_{\text{data}}(o_t) \neq P_{\pi_{\theta}}(o_t) $$
이런 문제들을 해결하기 위해 train 데이터셋을 augmentaion하기 위한 여러 가지 방법들이 사용됩니다. DAgger(Dataset Aggregation algorithm)가 대표적인 방법론이죠.
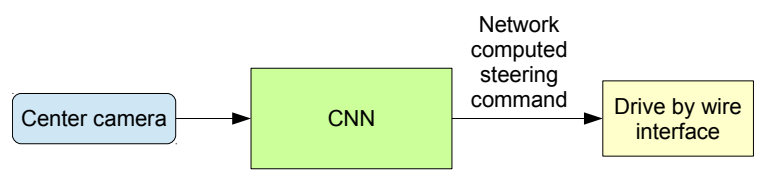
from End to End Learning for Self-Driving Cars , Bojarski et al. 2016
Our works
이 방법론을 적용하려고 고민하고 있을 때는 round 1을 진행 중이었기 때문에 금방 끝낼 수 있다는 안일한 생각에 박차를 가했는데요. round 1 같은 경우는 주변 지형지물이나 기타 변화 없이 static 한 환경에서 등속도로 뛰어가기만 하면 되는 문제였기 때문입니다. 정해진 action을 입력한다면 변경 없이 항상 정해진 observation state가 나오게 되고 이런 변화 없는 state만 입력된다면 Behavioral cloning으로 학습된 agent에게는 최적의 환경이라는 생각이었습니다. round 2의 경우 속도가 변화한다는 사실은 알고 있었지만, agent를 우선 기본속도인 1.25m/s로 기본적인 policy를 학습시켜놓고, 가변하는 속도는 학습된 agent를 갖고 재트레이닝하는 방식으로 접근하려고 했습니다.
그러나 이런 섣부른 기쁨?은 그리 오래가지 못했습니다. 앞선 posting에서 기술했듯이 action을 만들어내는 것이 실패했기 때문입니다. 그렇기 때문에 action 없이 observation state만을 이용한 방법론들을 탐색하게 되었습니다. 여러 논문과 아티클들을 리써치하던 중 적합한 논문을 발견하게 되었는데 그것이 Behavioral cloning from observation입니다.
Behavioral Cloning from Observation
Brief description
Behavioral Cloning from Observation(BCO)는 model-based 방법론입니다. Agent의 학습에는 그대로 BC를 사용하지만, observation으로부터 action을 예측하는 model이 추가됩니다. 이 Neural network로 만들어진 model(Inverse Dynamics Model)을 이용, 비어있는 Demonstration의 action을 inference 해서 BC에서 사용할 state, action을 만들어내는 것이죠.
논문에서 BCO(0)와 BCO(α)의 버전을 두었는데, 차이는 environment와 interaction을 일회성으로 하느냐 지속해서 하느냐의 여부입니다. BCO(0)는 model 학습 시 agent의 최초로 설정된 policy를 통해 interaction(Pre-demonstration)을 하여 만들어낸 state transition 데이터와 action 데이터만 이용합니다. BCO(α)는 agent의 update 된 policy를 이용하여 추가적인 interaction(Post-demonstration)를 수행하고 이 데이터들을 이용합니다. 여기서는 BCO(α)를 사용하였습니다.
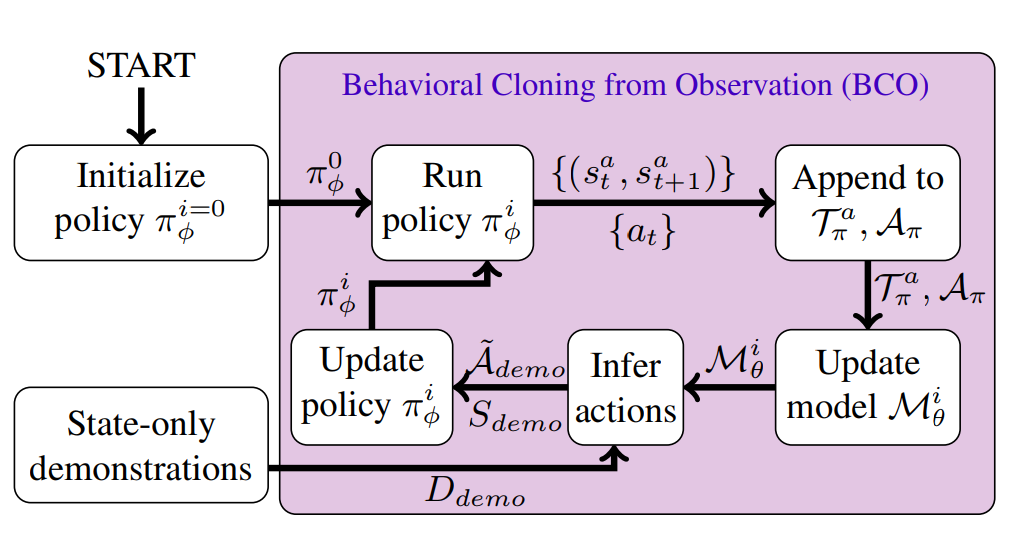
전체 프로세스를 간단하게 살펴보면 다음과 같습니다.
- Initialize policy $\pi_{\phi}^{i=0}$
- agent는 최초에 random policy로 시작
- 다음 반복
- Run policy $\pi_{\phi}^i$:
- agent는 각 time step 별로 environment와 interaction 하여 samples($s_t^a, s_{t+1}^a$), action($a_t$) pair 생성
- Append to $\mathcal{T}_{\pi_{\phi}}^a, \mathcal{A}_{\pi_{\phi}}$:
- 생성된 Samples는 $\mathcal{T}_{\pi_{\phi}}^a$ 에 action들은 $\mathcal{A}_{\pi_{\phi}}$에 넣어줌
- Update model $\mathcal{M}_{\theta}^i$:
- $\mathcal{T}_{\pi_{\phi}}^a, \mathcal{A}_{\pi_{\phi}}$를 사용하여 model 업데이트
- Infer action:
- model이 여러 demonstration trajectory의 모음인 $D_{\text{demo}}$ 사용하여 action inference
- Update policy $\pi_{\phi}^i$:
- agent의 policy 업데이트. demonstration state들과 inference 된 action들 $\mathcal{S}_{\text{demo}}, \tilde{\mathcal{A}}_{\text{demo}}$를 사용하여 behavioral Cloning 수행
- agent의 policy 업데이트. demonstration state들과 inference 된 action들 $\mathcal{S}_{\text{demo}}, \tilde{\mathcal{A}}_{\text{demo}}$를 사용하여 behavioral Cloning 수행
- Run policy $\pi_{\phi}^i$:
조금 더 엄밀한 정의를 이야기하자면 모델 $\mathcal{M}_{\theta}$ 를 학습시키는 것은 observed transitions를 가장 잘 만들어낼 수 있는 $\theta^*$를 찾는 것입니다. 수식으로 표현하면 다음과 같습니다.
$$ \theta^* = {arg\,max}_\theta \prod_{i=0}^{|\mathcal{I}^{\text{pre}}|}p_{\theta}(a_i | s_i^a, s_{i+1}^a) $$
이제 imitation policy $\pi_{\phi}$를 살펴보면 demonstration의 state들과 model을 통해 inference된 action의 pair {$s_i^a, \tilde{a}_i$}를 가장 잘 매칭 시킬 수 있는 $\phi^*$를 찾습니다.
$$ \phi^* = {arg\,max}_\phi \prod_{i=0}^{N}\pi_{\phi}(\tilde{a}_i | s_i) $$
Our works
Behavioral cloning 방법론을 택했던 또 다른 중요한 이유는 강화학습 분산처리를 위해 사용하고 있었던 framework인 Ray에서 agent가 미리 구현돼 있었다는 점입니다. 시간에 쫓기는 competition에서 이는 굉장한 이점이었습니다. 그러므로 새로운 학습방법론을 선정하는 과정에서 학습성능과 컨셉 못지않게 비중을 두었던 부분이 어떻게 하면 기존에 있던 모듈을 이용하여 구현시간을 단축할 수 있느냐는 점이었습니다. BCO는 이에 딱 알맞은 방법론이었죠. ray에서 이미 구현되어있는 BC agent를 활용해서 BCO agent를 구현하였습니다.1
그러나 결과는 생각보다 좋지 않았습니다. 결론부터 이야기하자면 behavioral cloning이 가진 근본적인 문제점이 해결되지 않았습니다. BCO에서 사용하는 action을 inference 해주는 model도 학습하지 못했던 observation 데이터가 들어온다면, 이상한 action을 결과로 만든다는 점이었습니다. 학습이 되지 않은 agent가 environment에서 얻어낼 수 있는 데이터는 고작 넘어지는 동작들뿐이었는데, Demonstration의 복잡한 달리기 싸이클에 대한 action은 당연히도 만들어 낼 수 없었습니다.
그래서 이러한 model을 학습시키기 위한 데이터 부족현상에 대한 해결책으로, DAgger와 비슷하게 train 데이터를 augmentation 하는 방법을 생각하게 되었습니다. 기존에 실험을 위해 여러 방법론으로 학습시키고 있었던 다른 agent들을 이용하여 state transition 데이터와 action 데이터를 만들어 내었습니다. BCO를 사용하여 학습하기 전에 미리 생성해놓은 데이터셋으로 model을 학습시킨 후, 이 pretrained model을 BCO agent 학습에서 이용하였습니다.
기대와는 달리 이 결과도 문제가 많았습니다. 다른 방식으로 학습시킨 agent의 동작과 demonstration 동작이 매우 달랐기 때문인데요. reward shaping을 통해 동작에 대한 최소한의 가이드만을 줘서 학습시킨 agent들은 달리는 동작이 각기 제멋대로였습니다. 이 agent들은 자세보다 달성하고자 하는 목적에 좀 더 맞는 형식으로 학습되기 때문에, 사람이 봤을 때 괴상해 보일 수 있지만, reward 상으로 봤을 때는 높은 점수를 얻습니다. 그래서 이 동작들은 demonstration의 달리기 동작처럼 일반적인 데이터가 거의 없었습니다. 아래 그림을 봅시다.


두 그림 모두 round 1 용 데이터들입니다. 좌측은 demonstration 데이터, 우측은 Augmented Random Search(ARS)로 학습시킨 agent의 결과입니다. 그림을 보면 알 수 있지만, 두 동작이 매우 다릅니다. 서 있는 자세에서 달리기까지의 출발 동작은 특히 차이가 심해서 문제가 많았습니다. model이 필요로 하는 참고할만한 transition 데이터가 매우 적었기 때문에, 제대로 된 action을 만들어내지 못했고 결과적으로 이 전략 또한 실패로 마무리되었습니다.
BC 계열 같은 경우 동작의 시퀀스를 알려줘서 자연스럽게 목적을 달성하게 됩니다. 우리가 goal이나 해야 할 task를 명확하게 지정해주지 않죠. agent에게 각 time step 별로 따라 해야 할 동작들만을 힌트로 제공합니다. 그렇다 보니 time step 별로 지정된 동작의 시퀀스가 한번 깨지게 되고 이런 부분이 쌓이게 되면 결과적으로 달성해야 할 목적에서 크게 벗어나게 됩니다.
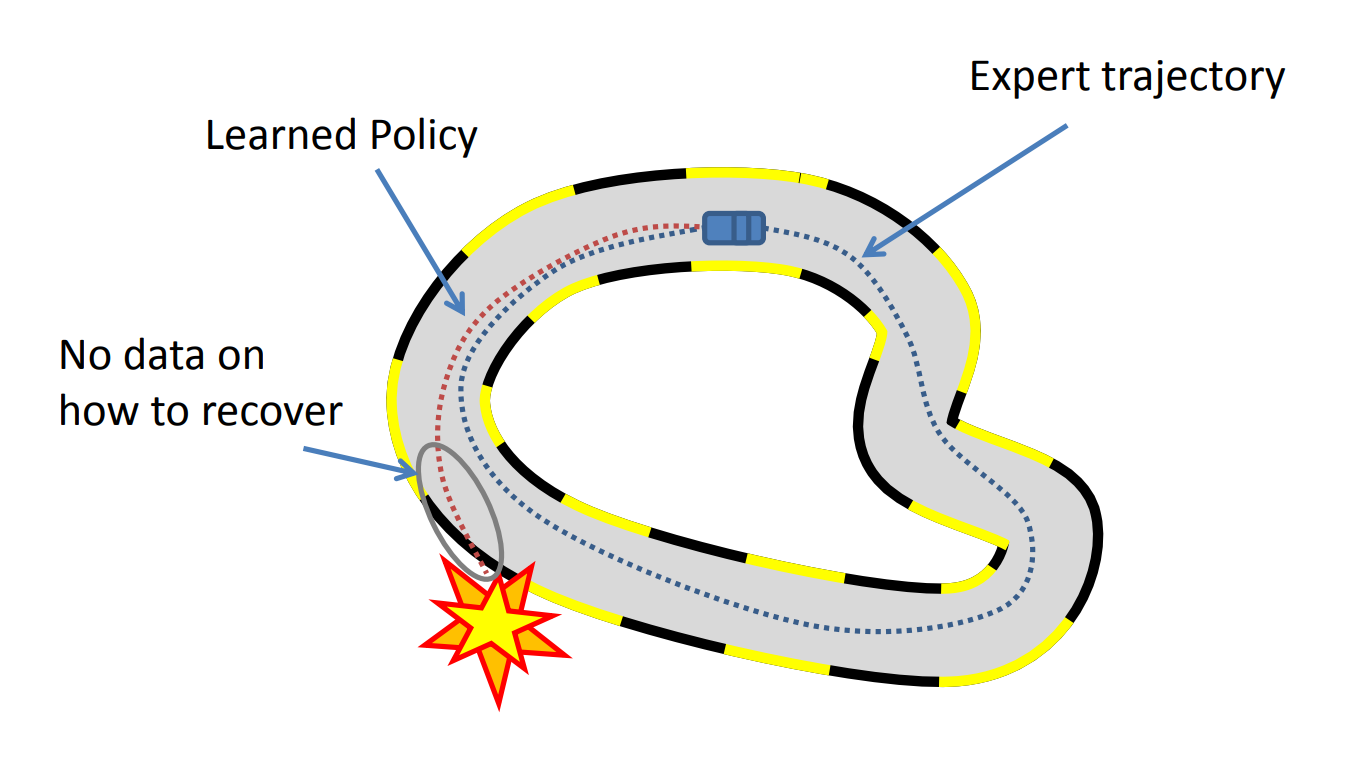
그러므로 자세를 참고는 하되 달성해야 할 목적을 계속해서 염두에 두고 수행하는, 나아가 참고해야 할 자세와 수행해야 할 목적의 비율을 조정해가며 실험해볼 수 있는 새로운 방법론이 필요하다는 생각을 하였습니다. 또다시 많은 탐색 과정을 거쳐 DeepMimic이라는 방법론을 사용하게 되었습니다.
DeepMimic
Brief description
DeepMimic은 Task 목적과 reference의 motion을 모사하는 것을 동시에 고려하는 방법론입니다. 이 방법론의 주요 아이디어는 크게 다음과 같습니다. - Reward - Imitation, Task - Reference State Initialization (RSI) - Early termination (ET) - Multi-Clip Reward
Reward - Imitation, Task
DeepMimic 아이디어 중 가장 핵심적인 부분으로 볼 수 있습니다. reward를 크게 2 부분의 합산으로 계산합니다. 얼마나 reference motion을 잘 imitation했는가와 agent가 수행하려는 task를 얼마나 달성했는가입니다. 우선 수식을 봅시다. 특정 time step(t)의 reward인 $r_t$는 다음과 같이 계산됩니다.
$$ r_t = w^Ir_t^I + w^Gr_t^G $$
- $r_t^I$: imitation reward
- $r_t^G$: task reward
- $w^I$: imitation weights
- $w^G$: task weights
여기서 imitation reward는 다음 수식과 같이 세분됩니다. 전체적인 수식을 먼저 보고, 각 내용에 대해 이야기해 보겠습니다.
$$ r_t^I = w^pr_t^p + w^vr_t^v + w^er_t^e + w^cr_t^c \ w^p = 0.65, w^v = 0.1, w^e = 0.15, w^c = 0.1 $$
- $r_t^p$: joint orientations reward
- $r_t^v$: velocity reward
- $r_t^e$: end-effector reward
- $r_t^c$: center-of-mass reward
이제 각 reward들을 조금 더 자세히 봅시다. 먼저 $ r_t^p $는 의 joint orientations의 유사 정도에 따라 reward를 주게 됩니다. 전체 imitation reward에서도 0.65로 가중치가 가장 큰데요. 그만큼 중요한 position 관련 factor라고 볼 수 있겠습니다. opensim에서 봐왔던것처럼, character의 joint의 angle들이 pose를 결정하기 때문입니다. 이것이 kinematics 데이터로 표현돼 있고요. 각 joint들의 least squares error의 가중치 합으로 계산됩니다. 수식을 보면 다음과 같습니다.2
$$ r_t^p = exp[-2(\sum_j|\hat{q}_t^j - q_t^j|^2)] $$
- $\hat{q}_t^j$: time step t일때, reference의 j번째 joint의 orientations
- $q_t^j$: time step t일때, agent의 j번째 joint의 orientations
두 번째로 velocity reward는 다음과 같이 계산합니다.
$$ r_t^v = exp[-0.1(\sum_j|\hat{\dot{q}}_t^j - \dot{q}_t^j|^2)] $$
- $\hat{\dot{q}}_t^j$: time step t일때, reference의 j번째 joint의 각속도
- $\dot{q}_t^j$: time step t일때, agent의 j번째 joint의 각속도
세 번째는 end-effector reward입니다. character의 손과 발같은 말단부(end-effector)의 위치가 reference와 유사한 정도를 계산합니다.
$$ r_t^e = exp[-40(\sum_e|\hat{p}_t^e - p_t^e|^2)] $$
- $\hat{p}_t^e$: time step t일때, reference의 e번째 end-effector의 위치
- $p_t^e$: time step t일때, agent의 e번째 end-effector의 위치
마지막으로 center-of-mass reward입니다. character의 질량중심(center-of-mass)의 위치가 reference와의 차이 정도에 따라서 reward가 달라집니다.
$$ r_t^c = exp[-10(\sum_e|\hat{p}_t^c - p_t^c|^2)] $$
- $\hat{p}_t^c$: time step t일때, reference의 center-of-mass 의 위치
- $p_t^c$: time step t일때, agent의 center-of-mass 의 위치
task reward는 agent가 달성하고자 하는 목표마다 달라지는데 기본적으로 수식의 형태는 imitation reward와 비슷하게 exp[sum(least square error)] 형태입니다.
의미들을 우선 살펴보았는데, reward 수식의 형태를 조금 더 자세히 분석해 보겠습니다. 수식의 가장 안쪽에 reference와 차이를 계산하는 error sum 부분을 봅시다.
$$ r_t^p = exp[\underbrace{-2(\sum_j|\hat{q}_t^j - qt^j|^2)}{\text{error sum}}] $$
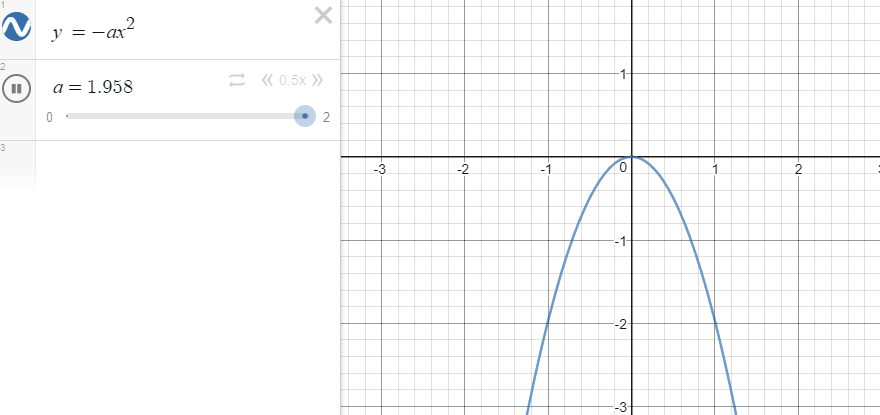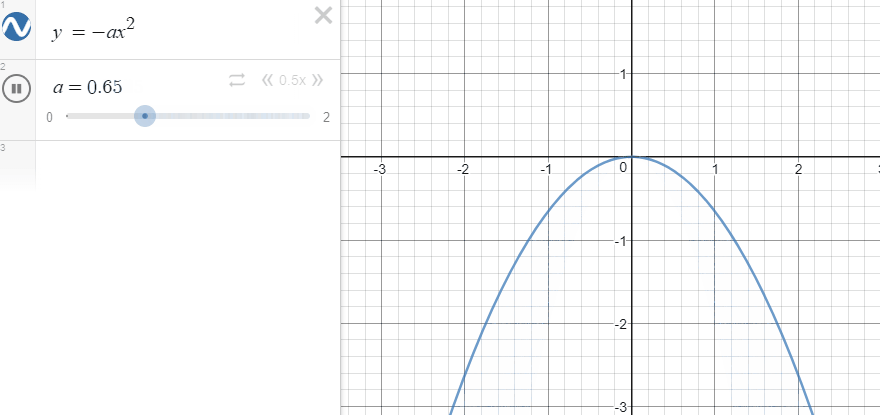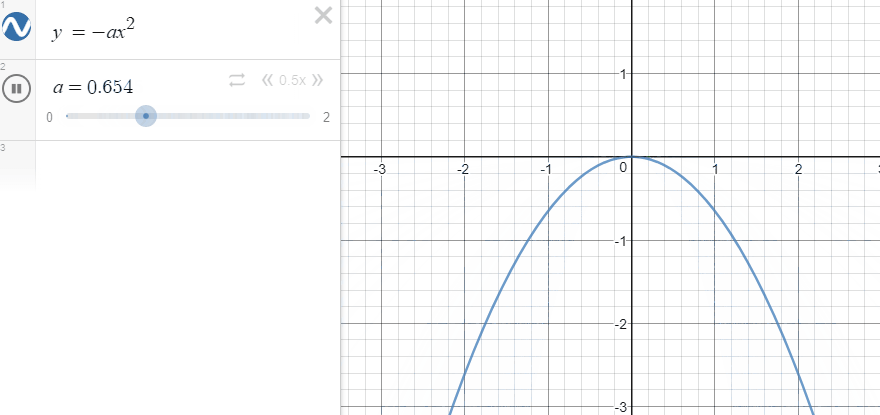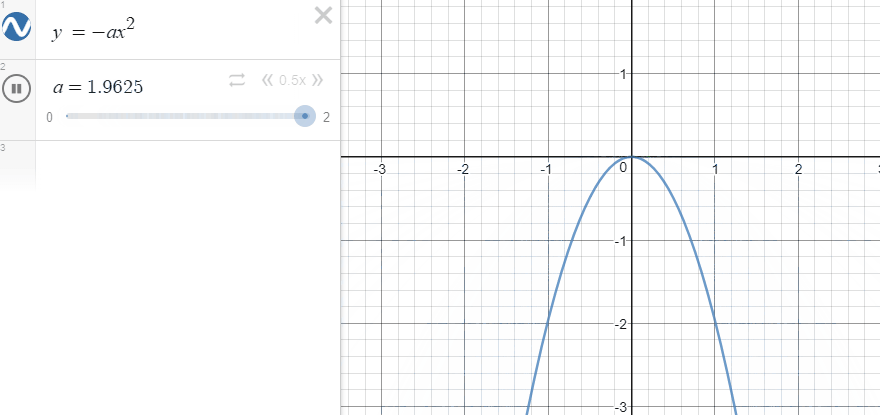
일단 $-x^2$의 그래프는 다음과 같은 형태입니다.
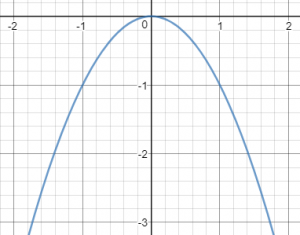
여기서 x를 reference와 agent의 특정 factor의 차이라고 보면, 차이가 커지면 커질수록 결괏값이 - 방향으로 커지고, 작아지면 작아질수록 0에 가까워집니다. 또한, factor의 차이가 작아지면 결과로 나오게 되는 결괏값의 차이가 작습니다. 그래프를 보면 직관적으로 알 수 있지만, 결괏값이 0에 가까워질수록 그래프가 뭉뚝해집니다. factor 간의 차이가 크면 클수록 더 강한 페널티를 준다고 볼 수 있습니다.
이제 바깥쪽 부분을 봅시다.
$$ r_t^p = exp[\text{error sum}] $$
exponential의 그래프는 다음과 같은 형태입니다.
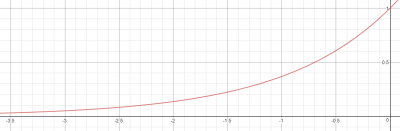
여기서 y축은 reward, x축은 위에서 설명한 error sum의 결괏값입니다. error sum 결괏값은 무조건 0보다 작은 값을 갖기 때문에 reward는 0~1 사이의 값을 갖게 됩니다. reward의 max 값이 1로 설정되는 셈이죠. 또한, error sum 결괏값(reference와의 차이)이 커지면 커질수록 x값은 exp그래프의 마이너스 방향으로 찍히게 되므로, 결과로 나오는 reward 값은 0에 한없이 가까워지게 됩니다. 이 차이 값이 -3 정도가 넘어가게 되면 얻게 되는 reward는 0.05 이하로 매우 낮아지게 됩니다. 여기서 알 수 있는 중요한 사실은 error sum의 결괏값이 어느 범위내에 들어오는 것을 적법한 reward로 인정할 것이냐를 error sum 수식 앞에 붙은 계수를 통해서 조절한다는 것입니다. 즉, reference와의 차이의 허용치를 조절한다는 말입니다. factor들은 다양한 물리량을 다룹니다. 어떤 것은 angle이 될 수도 있고, position 값들이 될 수도 있습니다. 이런 값들이 표현되는 고유한 형식에 따라 분포된 범위가 달라질 수 있습니다. 그리고 agent를 학습시키는 개발자들의 필요에 따라 유효한 범위를 조절하고 싶을 수 있습니다. 이런 부분들을 -2, -0.1, -40, -10과 같은 계수들을 통해 통제합니다.
Reference State Initialization (RSI)
일반적인 강화학습에서는 각 episode 시작 시에 initial state가 고정되어 있습니다. 게임을 시작할 때 시작 포인트와 캐릭터가 항상 똑같은 곳에 위치하는 것처럼요. 복잡한 동작을 배우기에는 이런 전략이 유효하지 않을 수 있습니다. 왜냐하면, agent의 policy는 항상 초기의 reference의 motion부터 차례대로 학습이 되는데, 초기 동작을 확실하게 마스터하기 전까지는 후속 동작을 학습하기 어렵습니다. 또한, 강화학습은 이전에 경험한 trajectory에서 높은 reward를 한 번이라도 얻어야만 제대로 된 학습이 가능한데, backflip같이 복잡하고 어려운 동작은 random exploration을 통해 성공적인 결과를 얻기가 매우 어렵습니다.
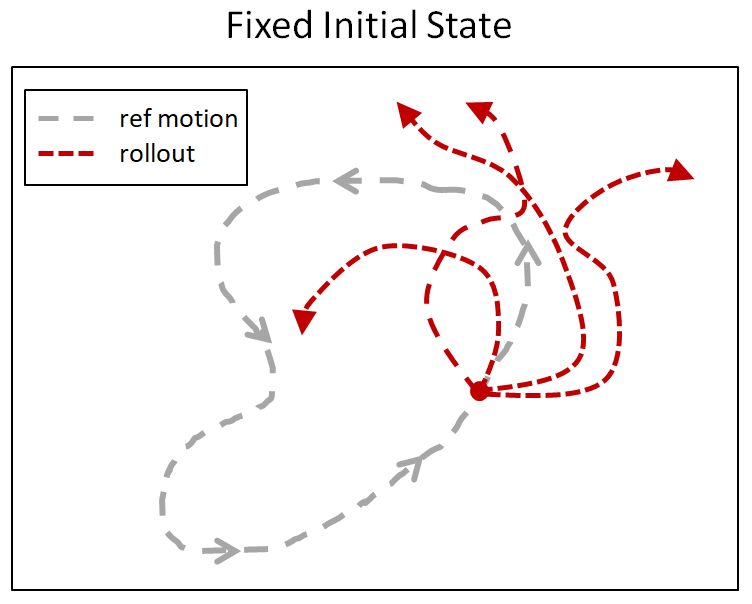
그러므로 RSI에서는 이 initial state를 변경합니다. reference motion의 state 중 한 포인트에서 무작위로 시작합니다. backflip으로 예를 들자면 어떤 때는 땅에서 시작할 수도 있지만, 어떤 때는 공중에서 몸이 돌아가는 중이 될 수도 있겠지요.
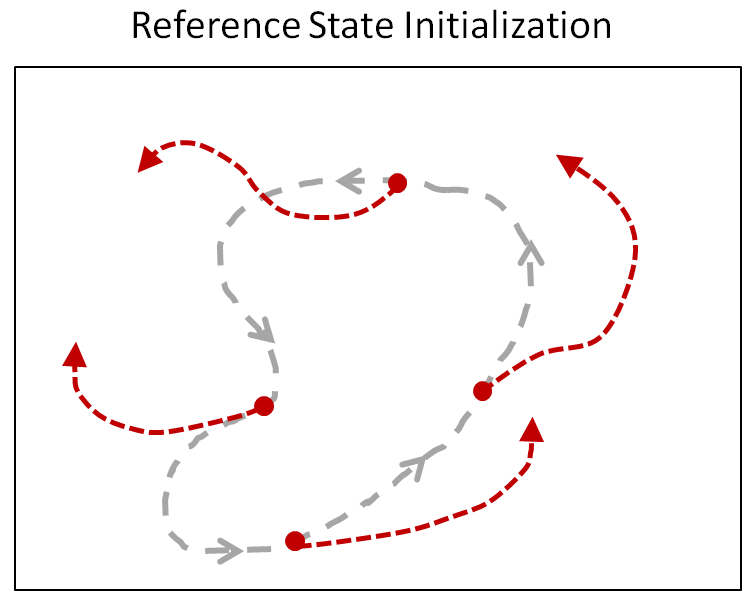
Early termination (ET)
agent가 특정 상황에 끼어서(stuck) 더는 학습을 진행할 수 없는 상태일 때, 학습을 일찍 종료시킵니다. 달리기를 배우는 환경인데 넘어졌다던가 하는 상황같이요. 이번 competition에서 골반의 위치가 특정 높이 이하로 떨어지면 ET를 수행시키는 코드가 기본적으로 들어가 있습니다.

Left: RSI+ET. Middle: No RSI. Right: No ET.
from Towards a Virtual Stuntman
Multi-Clip Reward
여러 reference motion을 활용하여 agent를 학습시킵니다. 매 time step 별로 여러 reference 중 적합한 것을 골라내는 manually crafted kinematic planner와 같은 방식보다 간단하면서 좋은 성능을 보였다고 합니다. 수식을 보면 명확한데, 해당 time step에서 가장 reward가 높은(max) reference의 reward를 사용합니다.
$$ r_t^I = \max_{j=1, … ,k}r_t^j $$
- $r_t^j$: j번째 motion clip의 imitation reward
Our works
DeepMimic을 적용하기 위해 opensim-rl의 reward function을 새로 정의하였습니다. DeepMimic에서 사용하였던 모든 주요 아이디어를 적용하려고 하였지만, RSI 같은 경우는 시뮬레이션 환경 자체를 뜯어고쳐야 하는 번거로움이 있었고, opensim 시뮬레이터를 그 정도로 깊게 연구할 시간이 없었기 때문에 Reward, ET, Multi-Clip Reward 정도만 적용할 수 있었습니다. 이 작업을 수행하며 고민했던 포인트는 다음과 같습니다.
- demonstration 데이터의 신뢰성 문제
- reference와 어떤 factor들의 수치를 비교할 것인가?
- reward들의 각각의 weight는 어떤 식으로 설정할 것인가?
- penalty 설정 여부
- task reward는 어떻게 설정할 것인가?
우선 demonstration의 신뢰성 문제부터 이야기해 보겠습니다. 기반이 되었던 kinematics같은 경우 실험데이터를 기본으로 작업이 되었지만, 수작업으로 데이터 수정을 통해 만들어냈기 때문에 이것이 실제 시뮬레이션 환경에서 동작할지 미지수였습니다.
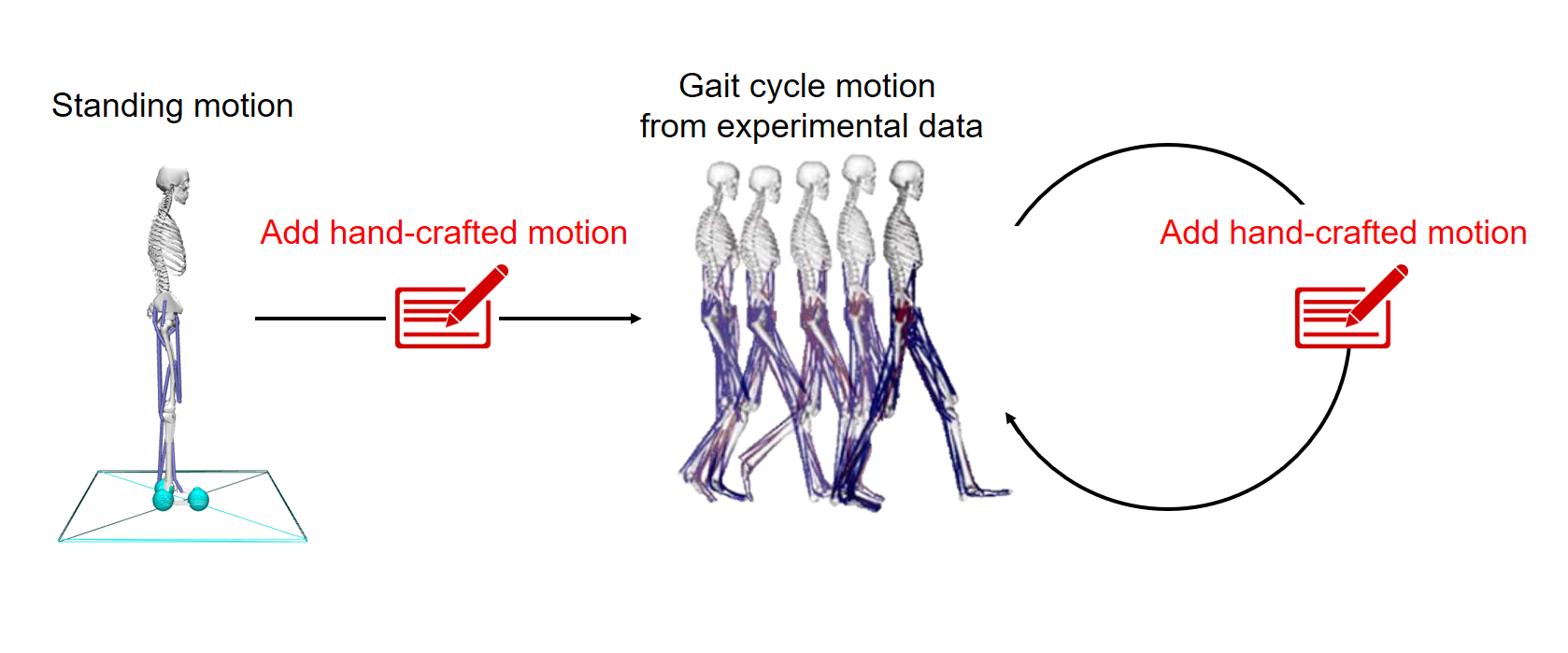
물론 수정한 kinematics가 동작하는 것을 opensim gui tool에서 확인하였지만, 이것은 근육의 action을 통한 동작이 아닌 단순히 pose들의 연속인 껍데기만 동작시킨 것이기 때문입니다. 앞선 BCO에서는 action 데이터를 만들 때 이미 시뮬레이션을 이용하기 때문에 그리 큰 문제로 생각하지 않았습니다. 그러나 여기서는 오로지 kinematics의 차이만을 가지고 학습에 사용하기 때문에 문제가 될 수 있었습니다. 그렇기 때문에 demonstration을 validation 하기 위해 여러모로 연구를 하였지만, 뾰족한 수를 찾을 수가 없었습니다. 결국, imitation reward와 task reward의 weight를 바꿔가며 실험적으로 성공적인 수치를 찾아내기로 하였습니다. 우선 만들어져 있는 demonstration에 대해 신뢰성이 떨어졌으므로 task reward weight를 조금 더 크게 잡는 쪽으로 실험을 시작하였습니다.
그리고 imitation reward를 설정하기 위해 어떤 factor들을 비교할 것인지를 알아내야 했습니다. 우선 현재 reference로 사용할 demonstration의 데이터 중 사용 가능한 필드들의 파악이 중요했는데요. 이것은 kinematics의 유효성과는 별개의 문제였습니다. 이전 posting에서 언급했듯 kinematics 데이터를 통해 demonstration의 state들을 만들어주는 opensim tool을 이용한 script의 결과가 얼마나 유효한 데이터인지 알 수 없었기 때문입니다. 이 프로그램의 역할을 조금 더 자세히 설명하면, kinematics 데이터에 있는 각 time step 별 position, joint angle 값들을 바탕으로 velocity, acceleration 같은 값들을 계산해서 state들에 추가합니다. 그래서 새로 추가된 데이터들의 유효성을 검증하고자, 다음 그림과 같은 과정을 사용하였습니다.
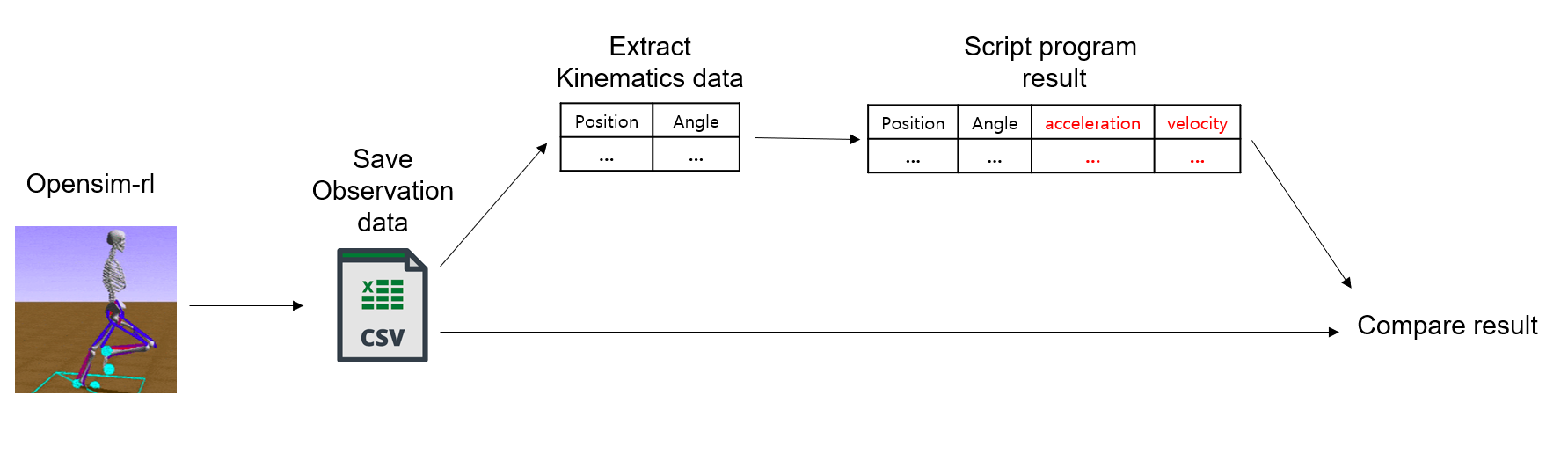
observation의 데이터에는 모든 position, velocity, acceleration 값들이 포함되어 있습니다. 여기서 얻은 데이터를 정답으로 했을 때, script를 통해 새로 만들어낸 데이터와 얼마나 유사한지를 검사하였습니다. 그 결과 acceleration을 제외한 값들은 80% 이상의 유사도를 보였고, 이 정도면 가중치를 통해 경중을 조절해가며 reference로 이용할만한 값이라고 판단했습니다. 그렇게 해서 최종적으로 reference로 사용하기로 한 factor들은 joint angle(pose), joint velocities, center-of-mass이 3가지입니다.
reward의 weight 및 penalty를 결정하는 일은 굉장히 시간이 많이 소요되는 일이었습니다. 끝이 언제일지 모를 hyper parameter tuning 작업이었는데요. imitation reward와 task reward의 비율부터, imitation factor들의 계수들, penalty 사용 여부 및 설정까지. 수정하고 실험해야 할 것들이 엄청나게 많았습니다. 또한, 실험을 진행하며 새로운 파라미터들을 추가해야만 했는데, kinematics 데이터의 불확실성 때문인 듯 rotation 값과 position 값들의 단순 비교만으로는 제대로 된 학습이 이루어지지 않았습니다. 해결책을 찾던 중 opensim IK tool에서 계산하는 것을 참고하여, joint들에 weight를 각각 따로 부여하여 중요한 부분은 오류에 민감하게 반응하도록 하니 학습이 이루어졌습니다. 그래서 최종적으로 아래 예제와 같이 parameter configuration을 만들고 hyper parameter tuning을 진행하였습니다.
************************************
reward configuration
step limit: 150
task reward: True
reward proportion:
- task: 3
- imi: 7
imitation reward weight:
- rot weight: -4
- vel weight: -0.1
- center pos weight: -10
- task weight: -2.5
joint weight:
- pelvis_tilt : 15
- pelvis_list : 5
- pelvis_rotation : 1
- hip_flexion_r : 3
- hip_adduction_r : 3
- knee_angle_r : 0.5
- hip_flexion_l : 3
- hip_adduction_l : 3
- knee_angle_l : 0.5
- ankle_angle_l : 2
demo files:
- /home/medipixel/demos/GIL02_free2_181019.xlsx
- /home/medipixel/demos/GIL02_free2_181026_3.xlsx
- /home/medipixel/demos/GIL02_free2_181026_2.xlsx
************************************
학습 시에 시뮬레이션을 처음부터 끝까지 돌려서 결과를 확인하지 않고 time step을 150~200 step 정도에서 끊고 추이를 지켜보았는데요. 튜닝을 위한 시간을 아끼기 위해서였기도 하지만 출발 자세가 제일 중요하다고 판단했기 때문입니다. 우선 이 과정이 가속을 시작하는 부분이었기 때문에 빠르게 목표 속도에 진입하기 위해 가장 중요한 부분이었고, gait cycle에 안정적으로 진입하기만 한다면 같은 움직임이 반복되기 때문에 큰 어려움 없이 학습이 가능하다고 생각했기 때문입니다. 여러 실험을 하며 다음과 같은 결과들을 얻을 수 있었습니다.




마지막으로 문제의 task reward 부분입니다. task reward 같은 경우는 deepmimic에서 사용하는 exp[error sum]형태를 사용하였는데, 출발 동작을 학습시킬 때까지는 문제없이 동작하는 것처럼 보였습니다. 그러나 제출 3일 전 거의 모든 parameter를 확정하고 본격적으로 최종 트레이닝을 시키려고 할 때 정작 이 task reward로는 전진이 안 된다는 것이 밝혀졌습니다.
물론 다른 전략으로 ARS agent를 트레이닝 중이어서 최악의 상황에도 제출은 할 수 있었지만, 여러 실험을 통해 출발자세를 다잡아놓은 agent를 포기하기 너무 아까웠습니다. 시간은 매우 촉박했지만, round 1 agent는 동작을 그나마 잘했던 것에 착안, 초심으로 돌아가서 round 1의 설정부터 살펴보기로 하였습니다.
Conclusion
round 2를 진행하며 task reward 부분을 deepmimic처럼 exp 형태로 바꾼 결정적인 이유가 있었는데, task reward를 기본 reward 형태로 설정해놓으면 전진하지 않고 그 자리에 가만히 서 있기 때문이었습니다. 그러나 round 1 같은 경우는 task reward를 변형하지 않고 기본형으로 쓰더라도 아무 문제 없이 학습이 잘되었죠. 심지어 imitation learning을 쓰지 않더라도요. 그런 이유에서 round 1의 reward를 살펴보며 차이점을 파악하려 했습니다. 이런저런 검토를 하던 중 중요한 점을 발견했습니다. 설명에 앞서 round 1과 round 2의 비교를 먼저 해보겠습니다. 우선 round 1 reward의 코드는 다음과 같습니다.
reward = 9.0 - (state_desc["body_vel"]["pelvis"][0] - 3.0)**2
이를 그래프로 그려보면 다음과 같습니다. x축은 속도 y축은 reward입니다.
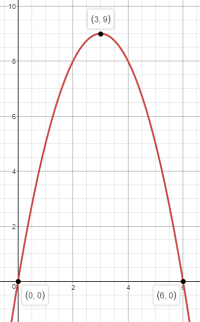
# target_vel = 1.25
penalty += (state_desc["body_vel"]["pelvis"][0] - state_desc["target_vel"][0])**2[0])**2
reward = 10.0
reward - penalty
그래프는 다음과 같습니다.
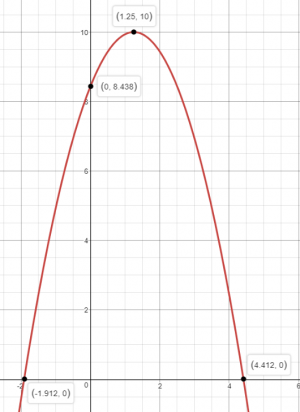
이 둘의 차이점은 그래프를 보면 명확해지는데, round 1이 전진에 성공했던 이유는 속도가 0일 때 reward를 얻지 못하기 때문입니다. 그에 반해 round 2는 당연히도 전진하지 않았습니다. 서 있으면(속도가 0일 때) 안전하게 8 이상의 reward 취득이 가능하기 때문입니다. 전진하는 것은 굉장한 risk를 짊어지는 일입니다. 현재 자세를 망쳐가며 불안정한 자세에 진입하는 것이기 때문이죠. 비교적 손쉽게 얻을 수 있는 reward를 포기하는 것 입니다. 그래서 상대적으로 쉬운 reward에 overfitting 되는 것이었습니다. 아주 재미있게도 약삭빠른 사람처럼 꼼수부터 배운 것이죠.
여기서 개선 가능한 부분을 발견했습니다. round 2의 리워드를 round 1처럼 속도가 0일 때 리워드 취득을 못하도록 바꾸는 것입니다.
그리고 더 나아가 오히려 가만히 서 있으면 penalty를 주는 방법을 적용했습니다. 속도가 0일 때 약간의 벌점을 받도록 했습니다. 벌점이 너무 세면 agent가 주눅?들어서 오히려 아무 행동도 취하지 못했습니다. 이렇게 task reward를 개편하니 드디어 전진을 시작했습니다. 그러나 가장 중요한 자원인 시간부족으로 학습을 완료할 수 없었습니다…. 마지막 학습 결과는 다음과 같습니다.

결국, 최종 결과물은 imitation learning이 아닌 ARS에서 학습하였던 agent가 되었습니다.
이번 competition에 imitation learning을 사용하여 학습시킨 결과물 제출은 실패했지만 위 일련의 과정을 진행하며 얻었던 경험과 지식은 앞으로 개발에 있어 피와 살이 될만한 것들이었습니다. 마지막으로 여기서 알 수 있었던 가장 중요한 점은 agent가 타고 올라갈 수 있는 reward function을 만들어줘야 한다는 점입니다. 적당한 채찍과 적당한 당근이 필요합니다. reward를 통해 나의 의도를 agent에 심을 수 있어야 합니다. 더하지도 덜하지도 않게 말이죠.
References
- Bojarski, M., Del Testa, D., Dworakowski, D., Firner, B., Flepp, B., Goyal, P., … & Zhang, X. (2016). End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316.
- Ross, S., Gordon, G., & Bagnell, D. (2011, June). A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics (pp. 627-635).
- Torabi, F., Warnell, G., & Stone, P. (2018). Behavioral Cloning from Observation. arXiv preprint arXiv:1805.01954.
- Peng, X. B., Abbeel, P., Levine, S., & van de Panne, M. (2018). DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills. arXiv preprint arXiv:1804.02717.
- Liu, M. Q., Anderson, F. C., Schwartz, M. H., & Delp, S. L. (2008). Muscle contributions to support and progression over a range of walking speeds. Journal of biomechanics, 41(15), 3243-3252.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., … & Petersen, S. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529.
- Xue Bin (Jason) Peng. (2018). Towards a Virtual Stuntman. Available at: https://bair.berkeley.edu/blog/2018/04/10/virtual-stuntman [Accessed 13 Dec. 2018].
- UC Berkeley. (2018). Deep Reinforcement Learning. Available at: http://rail.eecs.berkeley.edu/deeprlcourse/ [Accessed 11 Dec. 2018].
- Carnegie mellon university. (2018). Imitation Learning. Available at: http://www.andrew.cmu.edu/course/10-703/slides/Lecture_Imitation_supervised-Nov-5-2018.pdf [Accessed 12 Dec. 2018].
- 구현 내용에 대한 설명은 다음 posting에서 다룰 예정입니다. ^
- 논문에서는 이 수식에 - 기호가 아닌 $\ominus$ 가 사용됩니다. 이유는 논문에서 사용된 데이터가 joint orientation을 quaternion로 표현하기 때문인데, quaternion difference를 구하는 것을 $\ominus$라고 한 것입니다. 여기서는Towards a Virtual Stuntman에 언급한 것처럼 일반 - 를 사용하였습니다. ^
- 사실 round2 reward에는 z축 penalty가 더 있습니다. 다만 여기서는 가장 큰 점수 차이가 발생하는 부분이 x축 penalty이기 때문에 간소화를 위해 생략했습니다. ^